LLHD 借鉴了 LLVM 的设计思想,希望能为 HDL 和整个电路设计流程建立一个统一、完备的 IR 框架。
Introduction
Motivation
- 电路设计流程中会用到非常多的工具,这些工具大多以 HDL 为输入;但是 HDL 的标准非常复杂,以至于每个工具对标准的实现都不完全一致
- 设计者在设计时为了能兼容所有工具,会选择只使用 HDL 语言的一个“安全子集”,放弃使用一些高级特性
- EDA 市场被闭源、私有的工具链垄断,新的开源工具想要参与就必须先实现一套复杂的前端
Contribution
- 提出了 LLHD,一套能够贯穿整个电路设计流程的 IR 框架。为了能够适配电路设计不同阶段的需求,LLHD 采用了三层 IR(行为级、结构级、线网级)
- 展示了如何将工业级 HDL(SV 与 VHDL)映射到 LLHD,以及如何从行为级 IR 转换到结构级 IR
- 验证了这套工具可以在没有商业支持的条件下加入到工作流中(直接映射回 Verilog)
- 展示了 LLHD 能够描述复杂电路,并且在仿真上最多能比商业仿真器快 2.4 倍
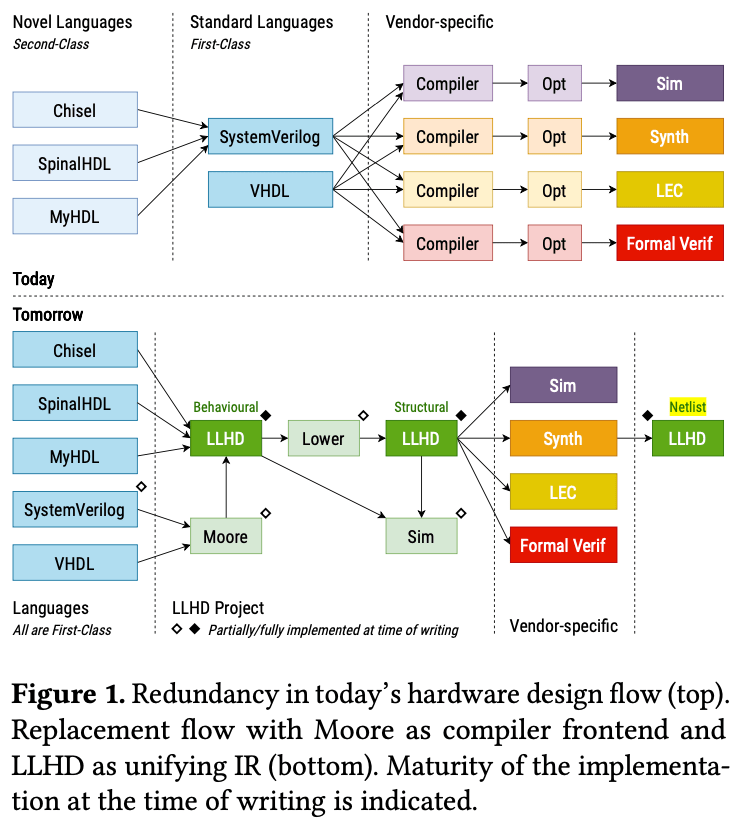
Figure 1: The structure between today’s hardware design and LLDH
但是本文的工作中只部分实现了从行为级 IR 到结构级 IR 的转换,并且没有涉及到从结构级 IR 到线网级 IR 的转换(因为这是 synthesizers 的工作)。
Proposed Method
LLHD IR
在设计上,LLHD 非常像 LLVM:
- 采用 SSA 来组织 data flow
- 有三种表示形式:in-memory, human-readable text, binary on-disk
- Typed:LLHD 采用了 LLVM 中的
void/iN/T*等类型,并添加了时间类型time、枚举类型nN、IEEE 1164 九值类型lN以及信号类型T$(N均表示一个正整数)
三级 IR
- Behavioural LLHD:用于仿真和验证,包含了所有的控制流
- Structural LLHD:由 entities 组成,用于综合,是 Behavioural LLHD 的子集。行为级 IR 在综合前会被转换到这一级
- Netlist LLHD(门级):仅用 entities 和 instructions 来表示线网的连接,是结构级 IR 的子集,由 synthesizers 生成
主要语法
- 三种组织结构:Functions、Processes、Entities
- Functions 和 processes 都是行为级的,用控制流组织,不可综合
- Functions 对应
function,不消耗时间,也不能驱动信号
- Functions 对应
- Processes 对应
task,可以消耗时间和驱动信号,输入输出必须是信号类型 - Entities 是结构级的,以数据流的方式组织,和真实电路对应
- 和真实电路一样,如果某个 instruction 的输入改变,则它会重新执行
- Entities 中用
reg和sig来声明寄存器和信号,用inst来实例化其他 entities 和 processes
- Functions 和 processes 都是行为级的,用控制流组织,不可综合
- Instructions
- LLVM 中常用的 instructions,比如
PHI/br等,还加入了mux指令来建模mux inst指令用于在 entities 中实例化 entities 和 processes,类似于电路连接- 信号类型
sig类似引用,类型为T$- 只能在 processes 和 entities 中使用
- 用
prb和drv读取和驱动
- 寄存器指令用于建模 registers/latches
- 参数包括变量类型、初始值以及一系列触发时存入的值和触发条件(包括
%trigger以及%gate) - 触发条件包括
low/high/rise/fall/both - 可以跟一个
if语句表示触发条件
- 参数包括变量类型、初始值以及一系列触发时存入的值和触发条件(包括
- Bit-precise Insertion/Extraction 指令
insf和extf用于存入和读取数组的某个元素或结构体的字段inss和exts用于存入和读取一个整数的某位或者某个切片
extf/exts/ 位移指令可以作用于信号,表示引用信号的切片- 对于引用的切片可以进行读取和写入
- 为了能够对应到硬件,这些切片的粒度让信号被切分
wait指令:当某个信号obsN改变了或过了%time时,跳转到resume_bb- 堆空间分配(来实现 SV 中的动态数组等特性)。对于可综合的电路,会用
mem2reg将其转换到寄存器 - Intrinsics:特殊的内置函数,比如
llhd.assert
- LLVM 中常用的 instructions,比如
HDLs to LLHD

Figure 2: Mapping HDL to LLDH
- SV
module/ VHDLentities:映射到entity - SV
always_*, initial, final/ VHDLprocess:映射到process,当输入信号改变时会重新执行- 组合逻辑(所有输出信号在所有控制流中都被赋值了):可以直接映射到逻辑门,类似纯函数
- 时序逻辑(存在输出信号在某些控制流中没有被赋值):对应 flip-flops 和 latches
- HDL 中允许设计者将两种逻辑写在一个 process 里,这需要 desequentialization pass 进行分离
- Generate Statements/Parameters:编译器前端展开(类似于 template)
- 验证相关的语句:映射到内置函数
llhd.*- 仿真:断言、输出错误信息
- 形式化验证:从这些内置函数中 extract 出信息,然后进行验证
- FPGA:用于硬件级实时的断言
Lowering
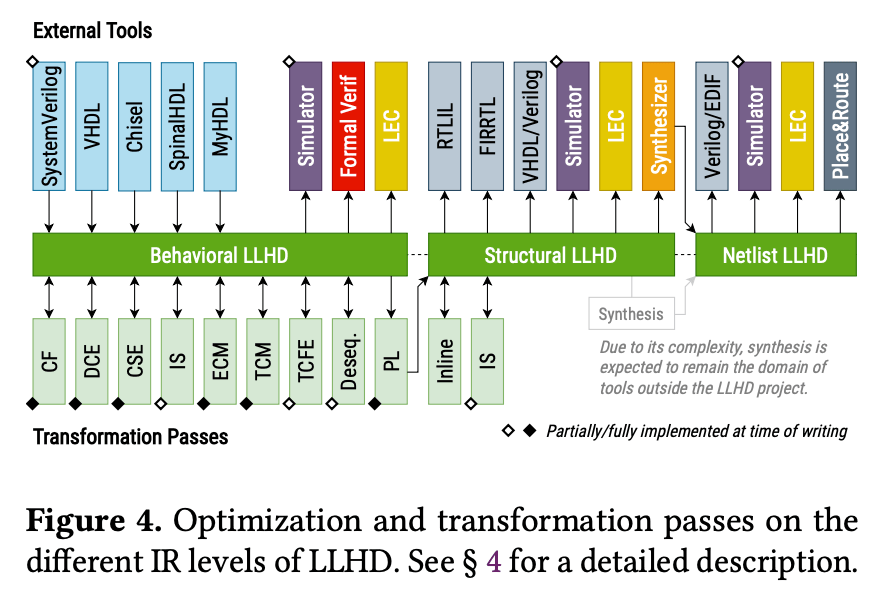
Figure 3: Passes for lowering
Lowering 的目标是将行为级 IR 转换为结构级 IR,以便进行综合。其中最关键的一步是将控制流转换为数据流(将 branches 转换成 branch-free 的代码),即将 processes 转换为 entities。

Figure 4: Lowering
这一步主要由下面几个 passes 完成(其中任意一步无法完成则视为不可综合)。
Basic
Constant Folding / DCE / CSE / Instruction Simplification (Combining) / Function Inlining / Loop Unrolling
ECM
Early Code Motion (Loop-Invariant Code Motion) 会尽量将指令前移,移出分支,以便后续消除控制流。
需要注意的是,prb 指令不能跨越 wait,否则会改变 prb 的结果。
TCM
Temporal Code Motion 会将移动 drv 信号到 temporal regions 末尾。
Temporal Regions
wait将代码在时序上划分为若干 Temporal Regions (TR),一个 TR 内的指令在同一个物理时间片内执行(组合逻辑)。因此不同 TR 中读取信号的结果可能不同。
TR 划分的规则如下:
- 入口块生成新 TR;
- 如果前驱块以
wait终结,则当前块生成新 TR; - 如果所有的前驱块属于相同 TR,则当前块也属于该 TR;否则当前块生成新 TR(因此每个 TR 有唯一的入口基本块)。
移动
drv由于同一个 TR 中读取的信号是相同的,因此最好将
drv移动到 TR 的末尾。TCM 会将
drv指令尽可能后移至 TR 的末尾单独的基本块中,步骤如下:- 首先为每个 TR 创建唯一的出口:如果 TR A 有多个出口流向 TR B,则先在 AB 间插入一个辅助基本块作为中介(由上面规则知,每个 TR 只有一个 entry block,因此这个操作一定能实现)
- 然后尝试移动
drv到末尾:- 先找 TR 的出口块与
drv所在块的公共支配者(如果没有则不操作,后续操作会 reject 这个程序) - 再收集公共支配者到
drv沿途的分支的条件 - 将
drv移动到 TR 尾部后,将收集到的分支条件取and作为这个drv指令的触发条件- 支配出口块的基本块的前驱是一定会执行的条件,因此可以忽略
- 所以
drv的执行取决于公共支配者到drv所在块
- 先找 TR 的出口块与
- 如果多个
drv指令驱动同一信号,则融合为phi指令*
TCFE
Total Control Flow Elimination 会消除控制流。
经过上面的步骤,只有 TR 的首尾块存在指令,中间都是空块,可以删除。
然后考虑将 phi 指令都转换为 mux 指令。mux 的 selector 的寻找方法和上面 drv 的触发条件相同。
完成后组合逻辑一定只有一个 TR,时序逻辑一定只有两个 TR(第一个用 wait 等待触发,第二个执行组合逻辑),其他的情况都算作不可综合 reject。
PL
Process Lowering 只处理组合逻辑,负责把只有一个以 wait 结尾的块的 process lower 到 entity。
只需要去掉基本块结尾的 wait,然后将其他指令原样移动到 entity 中。由于去掉了 wait 语句,为了保持语义等价,这里要求 wait 对所有 prb 的信号敏感。显然这点在组合电路中是成立的,否则 reject 程序。
Deseq
Desequentialization 处理时序逻辑,并会区分是 flip-flop 还是 latch。在前面时序逻辑已经被化简成了两个基本块(同时也是两个 TR)的程序。
首先将 drv 的触发条件化为析取范式(Disjunctive Normal Form,DNF),对于条件中的 eq 和 neq,也可以将其完全用与或非表达。
然后处理 DNF 中与边沿相关的条件。判断每个值采样时刻是在 wait 前的 TR 还是 wait 后的 TR。wait 前的 TR 表明采样到“旧信号”,drv 所在的 TR 是“新信号”。
再将 DNF 的子项改写为边沿触发的形式,规则如下(\(T_{\text{past}}\) 表示旧信号,\(T_{\text{present}}\) 表示新信号):
- \(\neg T_{\mathrm{past}} \land T_{\mathrm{present}} = T_{\mathrm{rising}}\)
- \(T_{\mathrm{past}} \land \neg T_{\mathrm{present}} = T_{\mathrm{falling}}\)
- \((\neg T_{\mathrm{past}} \land T_{\mathrm{present}}) \vee (T_{\mathrm{past}} \land \neg T_{\mathrm{present}}) = T_{\mathrm{both}}\)
未改写的项与边沿无关,作为 high / low 触发。
然后将成功识别出触发边沿 drv 转换为 reg 指令,并将相关的信号、延时等信息添加到对应 entity 中。剩余的部分作为组合逻辑,用 PL pass 转换,如果不通过则 reject。
Evaluation
仿真测试
所有的 LLHD 由前端 Moore 生成,且不进行任何优化。其中 LLHD-sim 是一个解释器;而 LLHD-Blaze 是一个 JIT 模拟器,会将 LLHD 翻译到 LLVM IR 再执行。
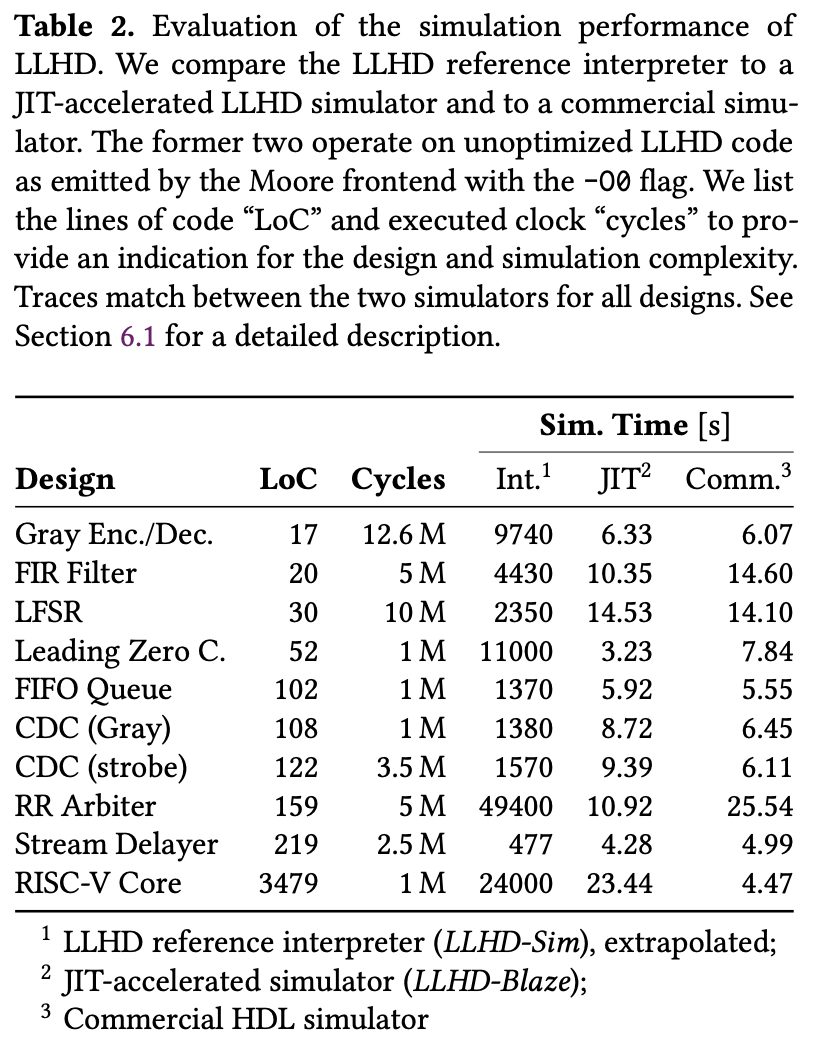
Figure 5: Similation time
IR 对比

Figure 6: IR comparison
- FIRRTL 是 Chisel 的后端 IR,定义了多层 IR 结构并且通过 transformations 进行转换
- μIR 主要用于加速器的结构级描述,并且迎合 HLS 的工作流
- RTLIL 支持电路的行为级描述,主要用于简化 Verilog 并用于综合
- LNAST 也支持电路的行为级描述,使用语言无关的 AST 描述,并提供转换的 pass
- CoreIR 聚焦于形式验证
其中,值得注意的是 Chisel 项目的 FIRRTL。FIRRTL 和 LLHD 的区别如下:
- FIRRTL 主要基于 AST,LLHD 基于 SSA
- FIRRTL 不能表示 testbench,也不能进行 simulation,因此不能用于高层 IR
- FIRRTL 不能表示四值逻辑或九值逻辑
- FIRRTL 没有清晰地对三层 IR 的区别进行定义