寄存器
通用寄存器
| Registers | Name | Usage |
|---|---|---|
$0 | $zero | 常量 0 |
$1 | $at | 保留给汇编器使用 |
$2 ~ $3 | $v0 ~ $v1 | 函数调用返回值 |
$4 ~ $7 | $a0 ~ $a3 | 函数调用参数 |
$8 ~ $15 | $t0 ~ $t7 | 临时变量 |
$16 ~ $23 | $s0 ~ $s7 | 需要保存的变量 |
$24 ~ $25 | $t8 ~ $t9 | 临时变量 |
$26 ~ $27 | $k0 ~ $k1 | 给操作系统使用 |
$28 | $gp | 全局指针 |
$29 | $sp | 堆栈指针 |
$30 | $fp | 帧指针 |
$31 | $ra | 返回地址 |
特殊寄存器
PC(Program Counter):用于存储当前 CPU 正在执行的指令在内存中的地址HI:这个寄存器用于乘除法。用来存放乘法结果的的高 32 位,或除法的余数LO:用来存放乘法结果的低 32 位,或除法的商
CP0 寄存器
CP0 是一个系统控制协处理器,主要用到 4 个:
SR:用于系统控制,决定是否允许异常和中断Cause:记录异常和中断的类型EPC:保存异常或中断发生时的PC值,即发送异常或中断时 CPU 正在执行的指令地址。当处理完成之后,CPU 会根据这个地址返回到正常程序中继续往下执行PRId:处理器 ID,用于实现个性的寄存器
指令
指令一般为 指令名 操作数 1, 操作数 2, 操作数 3,或者 指令名 操作数 1, 操作数 3(操作数 2)。一条指令中操作数可能是 0-3 个,可以是寄存器,立即数(常数,一般为 16 位)或标签。
标签用于表示一个地址,一般用于表示一个数据存取的地址,或者一个程序跳转的地址,最终由汇编器转换为立即数。
机器码
下面默认所有指令长度为 32 位。
在 RISC 中所有指令长度相同。在 CISC 中,指令数目多,且指令长度并不完全相同。
指令格式
MIPS 中指令被分为三种,R 型,I 型和 J 型。
R 型指令:一般用于运算,最多有 64 条(取决于 func 的长度)
op rs rt rd shamt func 6 bits 5 bits 5 bits 5 bits 5 bits 6 bits I 型指令:特点是有一个 16 位的立即数,包括立即数运算指令,比较跳转指令(offset),存取指令(offset)
op rs rt offset or immediate 6 bits 5 bits 5 bits 16 bits J 型指令:用于直接跳转,而不用 offset
op address 6bits 26 bits
还有些特殊的指令如 syscall 不遵从这些格式。
op:opcode,操作码,用于标识指令的功能func:用于辅助 op 来识别指令rs, rt, rd:通用寄存器的代号,并不特指某一寄存器,范围是$0 ~ $31(寄存器的机器码即对应的寄存器编号)shamt:移位值,用于移位指令offset:地址偏移量immediate:立即数(负立即数使用补码)address:跳转目标地址,用于跳转指令
指令编码
以 add 指令为例。

Figure 1: Add instruction in MIPS
根据编码可以把一个汇编指令翻译成机器码。
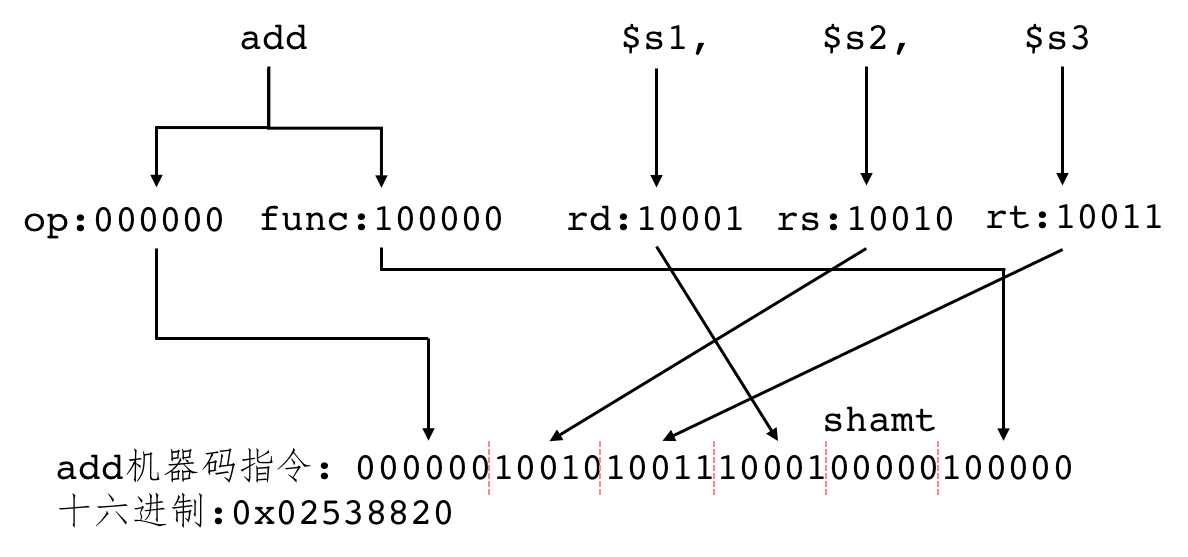
Figure 2: Add instruction in machine code
立即数一般会进行符号扩展,而逻辑运算中(andi、ori、xori)的立即数一般使用无符号扩展。
扩展指令
为了简化程序,mips 提供了一系列扩展指令。
如 li 指令用于给寄存器赋初始值,会根据具体需要翻译成 addiu 指令或 lui + ori 指令。
扩展指令可以在 Mars 文档的 Extended (pseudo) Instructions 查看。
伪指令
伪指令一般用来存储数据,不会被编译成机器码。
以下伪指令格式为
.instr [address],表示程序或者数据从[address]开始([address]可以省略,如果省略则为默认地址)。.data [address]:定义程序的数据段.text [address]:程序代码指令开始的标志
以下伪指令格式为
[name]: .instr [data1] [data2] [...]表示数据首地址的名字为[name]并将 data 按照写入对应的字_半字_字节(类似于一个数组)。.byte:申请一个 8 位变量(char).half:申请一个 16 位变量(short).word:申请一个 32 位变量(一个字)(int)
以下伪指令格式为
[name]: .asciiz "[content]"表示字符串名为[name],内容为"[content]"。.ascii:以字节为单位存储字符串,不包括\0.asciiz:以字节为单位存储字符串,自动添加\0
以下伪指令格式为
[name]: .space [n]表示数组名为[name],大小为[n]个字节。.space:申请若干个字节的未初始化的内存空间(数组,大小一般为变量数量* 4)
伪指令可以在 Mars 的 Directives 一栏查看。
.data
str : .asciiz "1234 + 5678" # char str[] = "1234 + 5678";
half : .space 2 # short half = 2;
i : .word 0xAABBCCDD # int i = 0xAABBCCDD;
array : .space 100 # char array[100];
.text
宏
宏可以带参数,也可以不带参数。如果带参数,参数前都需要加上 %。
.macro macro_name
# 代码段
.end_macro
# 带参数的宏
.macro macro_name(%parameter1, %parameter2, ...)
# 代码段
.end_macro
也可以用 .eqv [EQV_NAME] [string] 进行类似于 #define 的替换。
.eqv TUBECHAR_0 0x7E
注释
用 # 可以写注释,一般汇编会用大量的注释来辅助阅读。
常用指令
读存储器
lb rt, offset(base)读字节(带符号扩展)lb rt, offset(base)读字节(无符号扩展)lh rt, offset(base)读半字lhu rt, offset(base)lw rt, offset(base)读字
不存在 lwu,因为读字的时候无需进行扩展。
写存储器
sb rt, offset(base):写入字节sh rt, offset(base):写入半字sw rt, offset(base):写入字
加载立即数到高位
lui rt, immediate:将立即数加载到高 16 位
加载立即数到低十六位一般用 ori,二者配合使用可以加载一个 32 位数
lui $s7, 0x55AA
ori $s7, $s7, 0x1234
算术运算
加减
add rd, rs, rt:进行检测溢出的加法sub rd, rs rt:进行检测溢出的减法addu rd, rs, rt:进行不检测溢出的加法subu rd, rs rt:进行不检测溢出的减法addu rd, rs, rt:进行不检测溢出的加法(C 语言默认)subu rd, rs rt:进行不检测溢出的减法addi rt, rs, immediate:加一个立即数(有符号)addiu rt, rs, immediate:加一个立即数(不检测溢出)
由于 addi 本身可以加一个带符号数,所以不提供 subi。
乘除
mult rs, rt:有符号数相乘,结果高 16 位保存在hi中,低 16 位保存在lo中multu rs, rt:无符号数相乘div rs, rt:有符号数相除,余数在hi中,商保存在lo中divu rs, rt:无符号数相除mfhi rd:读取hi到rdmflo rd:读取lo到rdmthi rd:将rd写入himtlo rd:将rd写入hi
逻辑运算
and rd, rs, rt:与andi rd, rs, immediate:与上一个立即数or rd, rs, rt:或ori rd, rs, immediate:或上一个立即数xor rd, rs, rt:异或xori rd, rs, immediate:异或上一个立即数nor rd, rs, rt:或非
非指令可以用或非实现:nor $t0, $s0, $0。
移位指令
sll rd, rt, sa:逻辑左移(立即数)srl rd, rt, sa:逻辑右移(立即数)sra rd, rt, sa:算术右移(立即数)sllv rd, rt, rs:逻辑左移(寄存器)srlv rd, rt, rs:逻辑右移(寄存器)srav rd, rt, rs:算术右移(寄存器)
逻辑右移时最高位用 0,算术右移最高位用符号位填补。
使用寄存器移位时,只考虑低五位的数,不考虑高 27 位。
分支指令
beq rs, rt, label:相等则跳转bne rs, rt, label:不等则跳转blez rs, label:小于等于0则跳转bgtz rs, label:大于0则跳转bltz rs, label:小于0则跳转bgez rs, label:大于等于0则跳转slt rd, rs, rt:比较rs是否小于rt,结果存入rdslti rd, rs, rt:与立即数比较j label:无条件跳转jal label:跳转并将当前地址存入$rajr $ra:跳转到寄存器存储的地址
因为所有比较操作都可以用小于实现,所以只有 slt 是比较指令。
- 在 b 类指令中,imm 为 16 位带符号数,而且省略了最低两位(因为最低两位一定是
0),所以能转移的指令范围为 \(2^{16 + 2}\) 条,即 256KB(跳转到更多地方则需要借助j) - 在
j中,\(PC = PC_{31..28} \mid\mid instr\_index \mid\mid 0^2\),则转移的范围为 256MB - 在
jr中,可以跳转到 4GB 中的任意位置(注意jr是 R 型指令)
标签
汇编器会把标签翻译成 offset,即以当前的语句为基准,将偏移数 * 4(一条语句 4 bytes)得到 offset。
再跳转语句中,一般会指向标签的下一行,即 \(PC \leftarrow PC + 4 + \mathtt{sign\\_ext}(\mathtt{offset} \Vert 0^2)\)。
函数指令
jal label:调用函数,可以将当前位置的地址保存到$ra,并跳到label处jr src:返回调用点(通常为jr $ra)
伪指令
move rd, rs:赋值(addi rd, rs, $0)li rd, immediate:加载立即数(addi rd, $0, immediate或lui rt, immediate1+ori rd, rt, immediate2)la rd, address:加载地址到寄存器
空指令
nop:不执行任何操作(等价于sll $0, $0, 0)
系统调用 syscall
系统调用是专门用来实现输入输出,文件读取和终止运行等功能的一些指令。一般都是为 $a0 和 $v0 寄存器赋值,执行 syscall指令,然后汇编器就会根据$v0 寄存器中的值进行不同的操作。
字符串输出
la $a0, addr
li $v0, 4
syscall
整数输出
move $a0, $s0
li $v0, 1
syscall
整数读入
li $v0, 5
syscall
move $s0, $v0
结束程序
li $v0, 10
syscall
构造程序
控制语句
if
# 比较是否相等
bnq $s0, $s1, ELSE
THEN:
# then 对应的语句块
j ENDIF
ELSE:
# else 对应的语句块
ENDIF:
# 两个数字比较大小
slt $t0, $s1, $s0
bne $t0, $0, ELSE
THEN:
# then 对应的语句块
j ENDIF
ELSE:
# else 对应的语句块
ENDIF:
while
WHILE:
bnq $s0, $s1, END_WHILE
# 循环体
k WHILE
END_WHILE:
for
addi $t0, $0, 0
FOR:
slti $t0, $s0, 100
beq $t0, $0, END_FOR
# 循环体
addi $t0, $t0, 1
j FOR
END_FOR:
switch-case
<b 类指令 1> , CASE 1
<b 类指令 2> , CASE 2
j DEFAULT
CASE1:
# 语句 1
j END_SWITCH
CASE2:
# 语句 2
j END_SWITCH
# ...
DEFAULT:
# default 语句
END_SWITCH
数组
.data
array: .space 40 # n 个整数需要 4n 大小的地址
.text
li $v0,5
syscall # 输入一个整数
move s0, $v0 # $s0 = n
li $t0, 0 # $t0 循环变量
# 读入数组
loop_in:
beq $t0, $s0, loop_in_end # $t0 == $s0 的时候跳出循环
li $v0, 5
syscall # 输入一个整数
sll $t1, $t0, 2 # 获取地址 $t1 = $t0 << 2,即 $t1 = $t0 * 4
sw $v0, array($t1) # 把输入的数存入地址为 array[$t1] 的中
addi $t0, $t0, 1 # $t0 = $t0+1
j loop_in # 跳转到 loop_in
loop_in_end:
# ...
sll $t1,$t0,2 # $t1 = $t0 << 2,即 $t1 = $t0 * 4
lw $a0,array($t1) # 取出 array[$t1] 到 $a0 中
二维数组
.data
matrix: .space 256 # int matrix[8][8] 8*8*4 字节
# %i 为存储当前行数的寄存器,%j 为存储当前列数的寄存器
# 把 (%i*8 + %j) * 4 存入 %ans 寄存器中
.macro getindex(%ans, %i, %j)
sll %ans, %i, 3 # %ans = %i * 8
add %ans, %ans, %j # %ans = %ans + %j
sll %ans, %ans, 2 # %ans = %ans * 4
.end_macro
.text
# 存如数组,取出同理
getindex($t2, $t0, $t1) # 使用宏简化程序
sw $v0, matrix($t2) # matrix[$t0][$t1] = $v0
函数
调用函数是,函数调用处的地址保存在 $ra 中。输入保存在 $a0 ~ $a3,返回值保存在 $v0 ~ $v1(保存不下则放到栈里)。
栈从上到下增长,地址保存在 $sp 中。
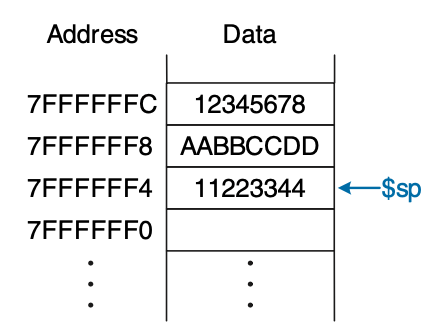
Figure 3: Stack
寄存器保护
调用函数前需要进行寄存器保护,并且需要在调用完后恢复。需要保护的寄存器分为 preserved($s0 ~ $s7、$ra、$sp)和 nonpreserved($v0 ~ $v1、$a0 ~ $a3、$t0 ~ $t9)。
按照约定,被调用函数使用 preserved 时必须进行保存,并在返回时恢复。而 nonpreserved 可以任意修改,其保护的任务交给调用者。即前者(如果子函数需要使用)在进入函数时保存,在退出前恢复。后者在调用前保存,在调用后恢复。
FN_1: # 调用者,保护 nonpreserved
# 其他代码
addiu $sp, $sp, -tempsize # 分配栈帧
sw $t0, [tempsize - 4]($sp) # 保存 $t0
# ...
sw $t7, [0]($sp) # 保存 $t7
move $a0, $t1 # 给参数赋值
# ...
jal FN_2 # 调用函数
lw $t7, 0($sp) # 恢复 $t7
# ...
lw $t0, [tempsize - 4]($sp) # 恢复 $t0
addiu $sp, $sp, tempsize # 回收栈帧
# 其他代码
END_FN_1:
FN_2: # 被调用者,保护 preserved
addiu $sp, $sp, -framesize # 分配栈帧
sw $ra, [framesize - 4]($sp) # 保存 $ra
sw $s0, [framesize - 8]($sp) # 保存 $s0
# ...
sw $s0, [framesize - 12]($sp) # 保存 $s7
# 主程序
lw $s7, 0($sp) # 恢复 $s7
# ...
lw $s0, [framesize - 12]($sp) # 恢复 $s0
lw $ra, [framesize - 4]($sp) # 恢复 $ra
addiu $sp, $sp, framesize # 回收栈帧
jr $ra # 结束函数
END_FN_2:
递归函数
递归函数和普通的函数调用一样,但是既要保存 preserved 寄存器,又要保存 nonpreserved 寄存器。
附加参数和局部变量
如果有保存不下的参数或者返回值,则应该将其保存在栈中,且多余的参数恰好放在 $sp 之上。
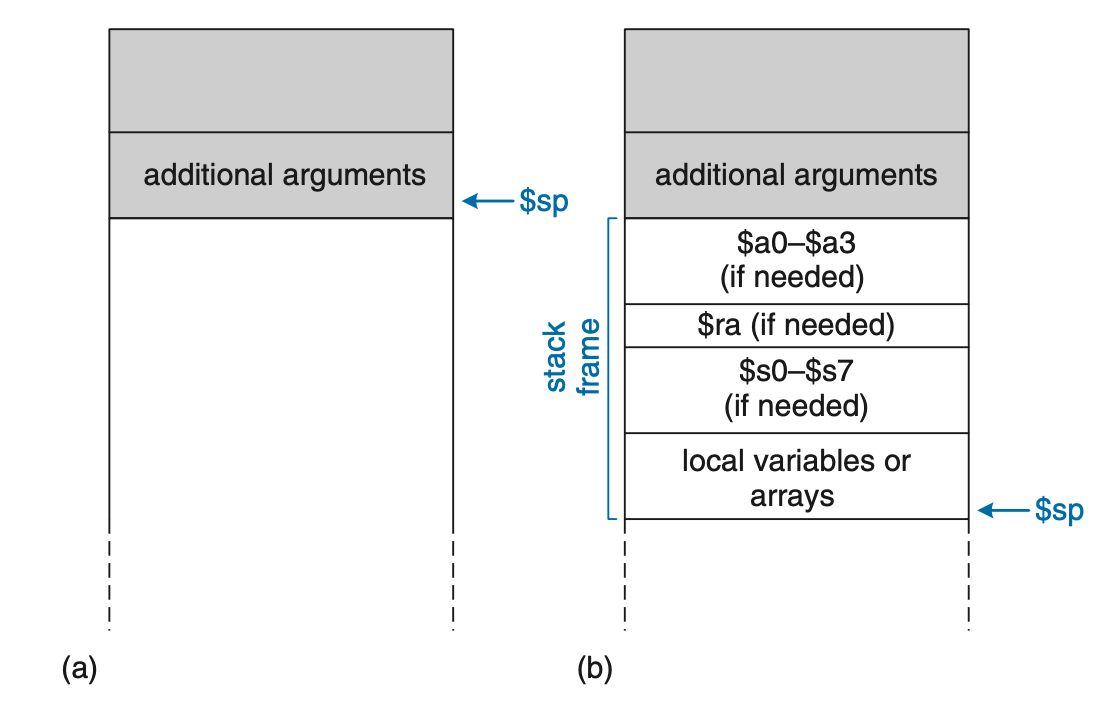
Figure 4: MIPS ABI
函数可以定义局部变量和数组,局部数组保存在栈上。
存储器与地址
可以用 30 位字(0x0000_0000 ~ 0x3FFF_FFFF)或 32 位字节(0x0000_0000 ~ 0xFFFF_FFFF)来描述地址。
将字节的最后两位去掉就可以得到对应的字,因此最后两位被称为偏移。
默认情况下汇编器会用字对齐的方式存储数据。
在存储器中,字节的组织方式有两种,即大端(big-endian)和小端(little-endian)。两种方法的字地址相同,但是一个字中的字节存储方式相反。在大端中高位(MSB)的字节地址较小,在小端中低位(LSB)的字节地址较小。
这里一般默认使用小端。

Figure 5: Big endian and little endian
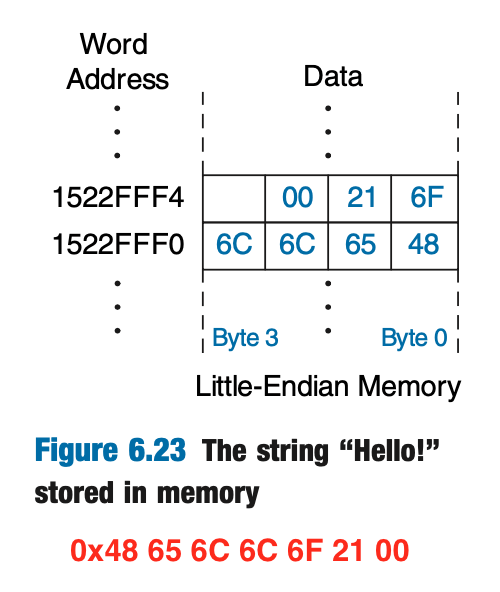
Figure 6: Little endian for string
寻址方式
- 寄存器寻址:直接使用寄存器
- 立即数寻址:寄存器 + offset
- 基地址寻址:立即数字段 + 寄存器,用于
lw等指令 - PC 相对寻址:label 的寻址方式,以当前地址 PC 和 offset 组成
- 伪直接寻址:用于
j和jal。
伪直接寻址中,理论上 j 和 jal 要用 32 位跳转目标地址(Jump Target Address,JTA)寻址,但是 opcode 占用了 6 位。考虑到字的最低两位为 0,则节省两位。而最高四位和 PC + 4 相同(这限制了跳转范围),所以刚好 26 位。
内存映射
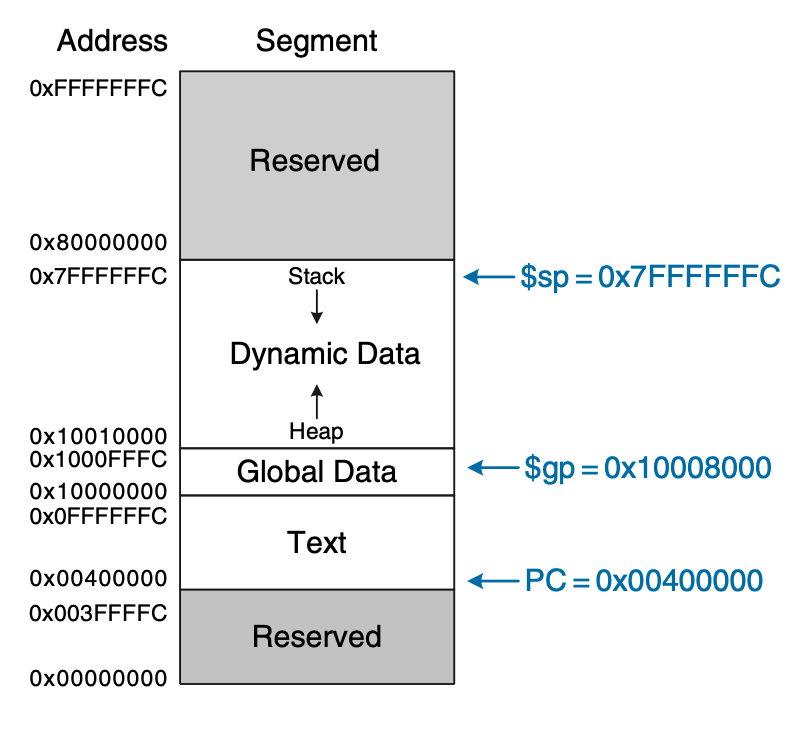
Figure 7: Memory mapping in MIPS
MIPS 的地址空间分为了 4 部分:
- 代码段(text segment)约 256 MB,最高 4 位为 0,所以
j指令可以任意跳转 - 全局数据段(global data segment)约 64KB,存放全局变量,可以用
$gp访问($gp默认为0x10008000) - 动态数据段(dynamic data segment)约 2GB,保存栈和堆。栈向下增长,堆向上增长,如果二者相遇则会引发溢出。
- 保留段(reserved segment)用于操作系统
浮点指令
MIPS 中的浮点指令定义了 32 个 32 位浮点寄存器($f0 ~ $f31)。一个 64 位双浮点数要占用两个寄存器。
| 名字 | 编号 | 用途 |
|---|---|---|
$fv0 ~ $fv1 | 0, 2 | 函数返回值 |
$ft0 ~ $ft3 | 4, 6, 8, 10 | 临时变量 |
$fa0 ~ $fa1 | 12, 14 | 函数参数 |
$ft4 ~ $ft5 | 16, 18 | 临时变量 |
$fs0 ~ $fs5 | 20, 22, 24, 28, 30 | 保存变量 |
浮点指令的 opcode 位 17(b10001),需要 funct 和 fop 来指明类型。单精度浮点数的 fop 为 16(b10000),双精度为 17(b10001)
单精度指令的助记符由 .s 结尾,双精度浮点数的助记符由 .d 结尾,如 add.s 和 add.d。
对于浮点分支指令,首先使用一个浮点指令(如 c.seq.s)清楚浮点条件标志(fpcond),然后根据 fpcond 执行 bclf 或 bclt。
对内存的操作可以使用 lwcl 和 swcl(双精度需要移动两次)。
| op | fop | ft | fs | fd | funct |
|---|---|---|---|---|---|
| 6 bits | 5 bits | 5 bits | 5 bits | 5 bits | 6 bits |
Mars
运行
首先需要进行配置:Settings → Memory Configuration,在弹出窗口中设置为 Compact,Data at Address 0。
导出
导出一般选择 Hexadecimal Text,可以导出数据段 .data 或代码段 .text。
对于数据段,范围为 0x00000000 - 0x00000ffc; 对于代码段,范围为 0x00003000 - 0x00003000 + (n-1)*4(n 为指令的个数),且导出的是机器码。
测试 CPU
Logisim
使用 Mars 编写程序,导出为十六进制文件后,在首行加入 v2.0 raw。
将其导入 IFU 模块中的 ROM(IM),运行 CPU。
Verilog
使用 Mars 编写程序,导出为十六进制文件,使用 $readmemh 读入到 IM 后进行模拟。
在 Isim 界面左侧选择 Memory 选项,即可选择查看 GPR、DM、IM 中的数据。
参考资料
- MARS 官网
- See MIPS Run Linux by D Sweetman
- Digital Design and Computer Architecture 2nd, Chapter 6